LSTM变体FC-LSTM:
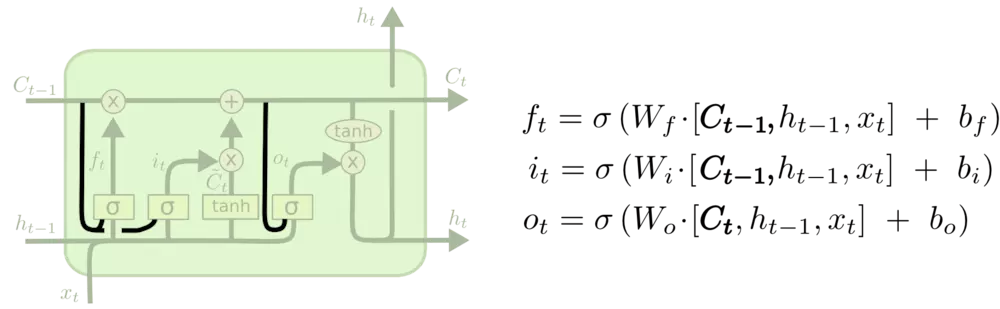
对应更新公式为:
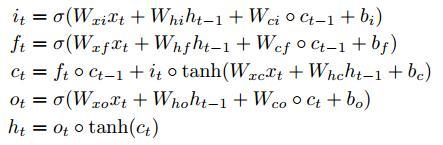
其中,空心小圆圈表示矩阵对应元素相乘,又称为Hadamard乘积。
ConvLSTM结构与FC-LSTM类似,不过将矩阵乘操作,换成了卷积操作。更新公式如下:
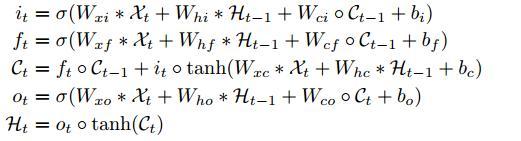
其中,it,ft,ct,ot,xt,ht都是三维的tensor,而在FC-LSTM中是二维的。
PyTorch实现ConvLSTM
此代码作者实现的ConvLSTM框图为:

引用代码:
import torch
import torch.nn as nn
from torch.autograd import Variable
class ConvLSTMCell(nn.Module):
def __init__(self, input_channels, hidden_channels, kernel_size):
super(ConvLSTMCell, self).__init__()
assert hidden_channels % 2 == 0
self.input_channels = input_channels
self.hidden_channels = hidden_channels
self.kernel_size = kernel_size
self.num_features = 4
self.padding = int((kernel_size - 1) / 2)
self.Wxi = nn.Conv2d(self.input_channels, self.hidden_channels, self.kernel_size, 1, self.padding, bias=True)
self.Whi = nn.Conv2d(self.hidden_channels, self.hidden_channels, self.kernel_size, 1, self.padding, bias=False) #为什么bias设成False? 因为Wx*跟Wh*在后面使用的时候,都是并存且相加的关系,所以可以合成一个,仅需要将任何一个的bias设为True即可。
self.Wxf = nn.Conv2d(self.input_channels, self.hidden_channels, self.kernel_size, 1, self.padding, bias=True)
self.Whf = nn.Conv2d(self.hidden_channels, self.hidden_channels, self.kernel_size, 1, self.padding, bias=False)
self.Wxc = nn.Conv2d(self.input_channels, self.hidden_channels, self.kernel_size, 1, self.padding, bias=True)
self.Whc = nn.Conv2d(self.hidden_channels, self.hidden_channels, self.kernel_size, 1, self.padding, bias=False)
self.Wxo = nn.Conv2d(self.input_channels, self.hidden_channels, self.kernel_size, 1, self.padding, bias=True)
self.Who = nn.Conv2d(self.hidden_channels, self.hidden_channels, self.kernel_size, 1, self.padding, bias=False)
self.Wci = None
self.Wcf = None
self.Wco = None
def forward(self, x, h, c):
ci = torch.sigmoid(self.Wxi(x) + self.Whi(h) + c * self.Wci) #与更新公式一致
cf = torch.sigmoid(self.Wxf(x) + self.Whf(h) + c * self.Wcf)
cc = cf * c + ci * torch.tanh(self.Wxc(x) + self.Whc(h))
co = torch.sigmoid(self.Wxo(x) + self.Who(h) + cc * self.Wco)
ch = co * torch.tanh(cc)
return ch, cc
def init_hidden(self, batch_size, hidden, shape):
if self.Wci is None:
self.Wci = Variable(torch.zeros(1, hidden, shape[0], shape[1])).cuda()#赋值初始状态为0
self.Wcf = Variable(torch.zeros(1, hidden, shape[0], shape[1])).cuda()
self.Wco = Variable(torch.zeros(1, hidden, shape[0], shape[1])).cuda()
else:
assert shape[0] == self.Wci.size()[2], 'Input Height Mismatched!'
assert shape[1] == self.Wci.size()[3], 'Input Width Mismatched!'
return (Variable(torch.zeros(batch_size, hidden, shape[0], shape[1])).cuda(),
Variable(torch.zeros(batch_size, hidden, shape[0], shape[1])).cuda())
class ConvLSTM(nn.Module):
# input_channels corresponds to the first input feature map
# hidden state is a list of succeeding lstm layers.
def __init__(self, input_channels, hidden_channels, kernel_size, step=1, effective_step=[1]):
super(ConvLSTM, self).__init__()
self.input_channels = [input_channels] + hidden_channels #将整个ConvLSTM的传入channel数添加到List头上, 前length-1个分别为所有ConvLSTMCell的input_channels数目;input_channels列表中对应的值则分别为所有ConvLSTMCell的hidden_channels数目。
self.hidden_channels = hidden_channels
self.kernel_size = kernel_size
self.num_layers = len(hidden_channels) #ConvLSTM中的layer数。为啥不跟RNN/LSTM一样,直接填个数就可以了呢?RNN/LSTM中,调用PyTorch的nn.RNN/nn.LSTM确实只需要传个num_layers进去就可以搭建多层网络,但其每层的hidden_size是一致的。如果需要搭建不一致的多层网络,依旧需要通过调用多次nn.RNNCell/nn.LSTMCell进行拼装。ConvLSTM网络深度
self.step = step #代表序列长度,ConvLSTM网络宽度
self.effective_step = effective_step #取哪一个/多个ConvLSTMCell的预测结果进行输出
self._all_layers = []
for i in range(self.num_layers):#组装ConvLSTM
name = 'cell{}'.format(i)
cell = ConvLSTMCell(self.input_channels[i], self.hidden_channels[i], self.kernel_size)#组装每一层结构
setattr(self, name, cell)
self._all_layers.append(cell)
def forward(self, input):
internal_state = []
outputs = []
for step in range(self.step):
x = input
for i in range(self.num_layers):
# all cells are initialized in the first step
name = 'cell{}'.format(i)
if step == 0: #初始化零状态h0,c0;网络WC*
bsize, _, height, width = x.size()
(h, c) = getattr(self, name).init_hidden(batch_size=bsize, hidden=self.hidden_channels[i],
shape=(height, width))
internal_state.append((h, c)) #添加保存零状态
# do forward
(h, c) = internal_state[i] #取前一时刻状态量
x, new_c = getattr(self, name)(x, h, c) #调用该层ConvLSTMCell
internal_state[i] = (x, new_c) #更新状态量
# only record effective steps
if step in self.effective_step:
outputs.append(x) #添加想要保留的预测结果
return outputs, (x, new_c) #返回想要的预测结果项,末状态本文添加备注,便于理解,代码来自:https://github.com/automan000/Convolutional_LSTM_PyTorch
其对应的(多step)序列网络框图为:

但我的需求是:

有类似需求的,可以拉取我的代码,地址: https://github.com/Winsolider/ConvLSTM/blob/master/ConvLSTM.py。
 QQ客服
QQ客服 新浪微博
新浪微博