RNN(Recurrent Neural Network)是一类用于处理序列数据的神经网络,最常见的是时间序列、文字序列。
基础神经网络(常规CNN)与RNN
我们从基础的神经网络中知道,神经网络包含输入层、隐层、输出层,通过激活函数控制输出,层与层之间通过权值连接。激活函数是事先确定好的,那么神经网络模型通过训练“学“到的东西就蕴含在“权值“中。
基础的神经网络只在层与层之间建立了权值(U,V)连接,如下图所示:

RNN最大的不同之处就是在神经元之间也建立的权值(U,V,W)连接。如图:
图中x代表输入,h代表隐藏层,o代表输出,y代表样本给出的确定值,L代表损失函数,U,V,W代表权值。
RNN的结构变体



RNN的训练方法——BPTT
BPTT(back-propagation through time)算法是常用的训练RNN的方法,其实本质还是BP算法,只不过RNN处理时间序列数据,所以要基于时间反向传播,故叫随时间反向传播。BPTT的中心思想和BP算法相同,沿着需要优化的参数的负梯度方向不断寻找更优的点直至收敛。
公式推导请参考:https://blog.csdn.net/zhaojc1995/article/details/80572098
参考:【1】https://blog.csdn.net/zhaojc1995/article/details/80572098
【3】https://baijiahao.baidu.com/s?id=1622177190450583829&wfr=spider&for=pc
RNN实验
pytorch中的RNN,torch.nn.RNN():

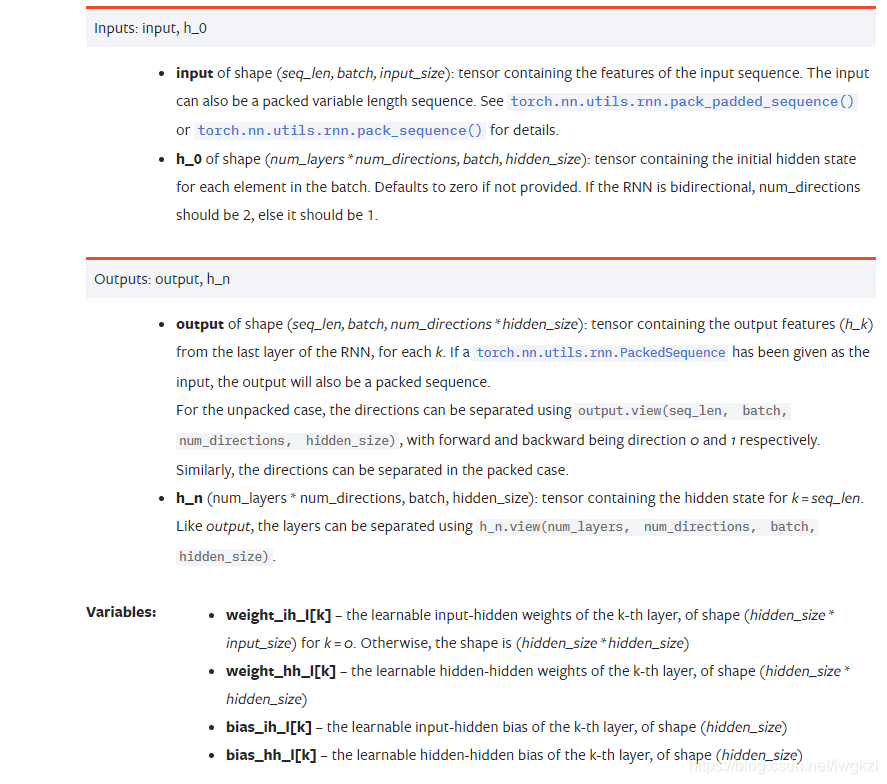
| 参数 | 含义 | 注意 |
| input_size | 输入 x 的特征维度数量 | 是特征维度,不是序列长度 |
| hidden_size | 隐状态 h 中的特征数量 | hidden层节点数目 |
| num_layers | RNN层数 | hidden层数目,决定网络深度,不是宽度 |
| nonlinearity | 指定非线性函数使用 [‘tanh’|’relu’]. 默认: ‘tanh’ | |
| bias | 如果是 False , 那么 RNN 层就不会使用偏置权重 b_ih 和 b_hh, 默认: True | |
| batch_first | 如果 True, 输入 Tensor 的 shape 为 (batch, seq, feature),输出一样 | 默认是False, 输入Tensor的shape 为 (seq, batch, feature),输出一样 |
| dropout | 如果值非零, 那么除了最后一层外, 其它层的输出都会套上一个 dropout 层 | |
| bidirectional | 如果 True , 将会变成一个双向 RNN, 默认为 False |
实验演示代码
正弦预测余弦
import torch
from torch import nn
import numpy as np
class Rnn(nn.Module):
def __init__(self, INPUT_SIZE):
super(Rnn, self).__init__()
self.rnn = nn.RNN(
input_size=INPUT_SIZE,
hidden_size=32,
num_layers=2,
batch_first=True
)
self.out = nn.Linear(32, 1)
def forward(self, x, h_state):
r_out, h_state = self.rnn(x, h_state)
outs = []
for time in range(r_out.size(1)):
outs.append(self.out(r_out[:, time, :]))
return torch.stack(outs, dim=1), h_state
# 定义一些超参
TIME_STEP = 10
INPUT_SIZE = 2
LR = 0.02
# “看”数据
# plt.plot(steps, y_np, 'r-', label='target(cos)')
# plt.plot(steps, x_np, 'b-', label='input(sin)')
# plt.legend(loc='best')
# plt.show()
# 选择模型
model = Rnn(INPUT_SIZE)
print(model)
# 定义优化器和损失函数
loss_func = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=LR)
h_state = None # 第一次的时候,暂存为0
for step in range(300):
start, end = step * np.pi, (step+1)*np.pi
steps = np.linspace(start, end, TIME_STEP, dtype=np.float32)
x_np = np.sin(steps)
y_np = np.cos(steps)
x = torch.from_numpy(x_np[np.newaxis, :, np.newaxis])
y = torch.from_numpy(y_np[np.newaxis, :, np.newaxis])
prediction, h_state = model(torch.cat((x,x), 2), h_state)
h_state = h_state.data
loss = loss_func(prediction, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("x:")
print(x)
print("y:")
print(y)
print("predict:")
print(prediction) QQ客服
QQ客服 新浪微博
新浪微博